Continuous delivery with Jenkins and Heroku
Some time ago I read Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation, by Jez Humble. It is a great book I totally recommend. In this post, I would like to talk about our approach for implementing its principles using Jenkins and Heroku in zendone(https://www.zendone.com).
Continuous delivery extends the ideas of continuous integration introducing the pattern of a deployment pipeline, which according to the book is:
An automated implementation of your application’s build, deploy test and release process.
Automated builds are a key aspect of Continuous Integration, and deployment pipelines elaborate on the concept of staged builds: automated build phases that are chained, having the application deployed in the last step if all the previous stages are built successfully.

Each time a change is detected in the source code repository the deployment pipeline starts:
-
The commit stage executes the unit tests and may run other processes, like analysis of coding standards or code coverage. It asserts the system works at the technical level.
-
The acceptance stage executes the tests that exercise the system as a whole, asserting that it works at the functional and nonfunctional level.
-
The manual testing stage tries to detect defects not caught by the automated tests and check that the system fulfills its requirements. It typically includes exploratory testing and user acceptance testing.
-
The release stage delivers the system to its users. This may include distributing the packaged software or, in the case of web applications, deploying the application on the production server.
As the build advances, the stages become slower but the confidence in the readiness of the build increases. For example, unit tests are fast, but they won’t detect integration bugs. While acceptance tests are slow but they check all the components assembled and working together.
The book explains in detail the deployment pipeline pattern, and it also reviews many technical solutions for implementing it.
So we wanted to apply these ideas to the way we develop zendone. Our ingredients are:
- A Rails backend and a Javascript-heavy web client.
- Heroku as our hosting platform.
- Jenkins as our CI server.
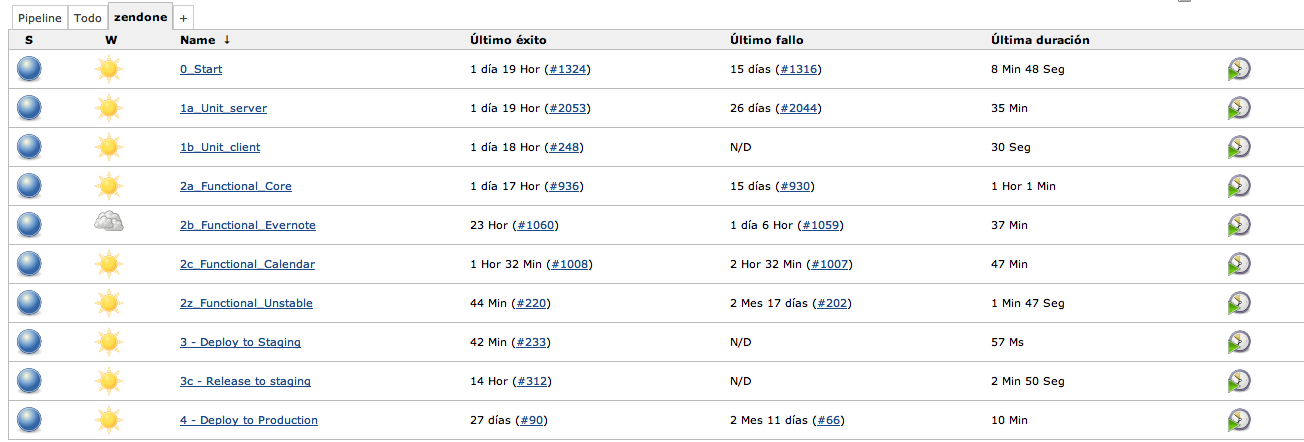
Pipeline design
We designed a pipeline based on the general structure proposed in the book and implemented it with the following build steps:
- Commit stage
- Acceptance stage (Cucumber tests)
- Functional Core
- Functional Evernote
- Functional Calendar
- Manual testing stage
- Release to staging environment
- Release stage
- Release to production environment
To advance between stages, all the corresponding tasks must be properly executed. For example, the build won’t develop to our staging environment until all our acceptance tests have passed.

Commit stage
When a change is detected in our Github repository the build starts. It first prepares the environment to run the build. It installs all the gems needed, resets the database, cleans temporary directories, etc.
After everything is set up, it automatically labels the code in Github with the build version, which includes the build number extracted from Jenkins. That will allow you to trace each build with the specific code it executed.
The build runs the suite of RSpec tests for the Rails server and also the suite of Jasmine tests for the Javascript client. Although we don’t pay too much attention to them, we also collect RCov metrics of code-coverage for our RSpec tests.
Acceptance stage
Once the unit tests pass, the build enters into the acceptance stage. We use Cucumber with Capybara and Selenium web driver for building our suite of functional tests.
A serious problem when you run your tests in a real browser with Webdriver if that they are very slow. We palliated this problem by:
- Parallelizing. We parallelized the execution of our suite using parallel_tests. We are currently running our Cucumber features with 5 browsers in parallel.
- Slicing. We divided our big suite of tests into 3 big categories: Core, Calendar, and Evernote, so we have smaller builds that fail earlier and let us test specific parts of our app more easily.
But even with this measures, running functional tests in a browser is very slow. Our full suite takes about 2 hours to run. But we believe that it is a very valuable asset for us. When it passes we are pretty confident that everything will work right in the build. That level of confident is priceless, especially when you are a small team as we are.
There are different opinions in the community about the value of real integration tests. Some people like Uncle Bob opine that you should focus on testing the boundaries the UI uses for speaking with the system. This will let you keep your acceptance tests fast. I think that, in the case of web apps with heavy javascript clients, real tests really add a huge value. Being able to specify what the user expects and how the system should respond, and with those, testing all the layers of your application (web UI, Javascript, persistence, external systems’). With the experience of zendone, these tests have prevented us from introducing bugs in countless occasions (despite having a good unit suite for both the client and the server components).
Another discussion is whether to use Cucumber or not. You can perfectly use Capybara for writing integration tests without Cucumber (for example, combined with RSpec). Cucumber certainly adds another abstraction layer that some people consider unneeded. My opinion is that I like how Cucumber makes you focus in describing how your system should behave. But the important thing is having a good acceptance suite executed in a real browser, whatever technology you use for implementing it.
Release to staging
If all the acceptance tests pass, the application is automatically deployed to our staging environment. This environment is identical to our production environment.
We typically run some manual tests in the staging environment just to be certain that the latest additions are working right, although in many minor builds we skip this phase.
We decided that we didn’t want to have the application automatically deployed to production if all the automated tests passed. We just considered it too risky. We prefer to keep a manual trigger deploying to production.
Release to production
When we want to release to production, we launch the ‘Release to production’ task.
While we are making backups of our data on every hour, we do a backup just before releasing to production, just in case we have to revert to the previous build if something goes wrong. Heroku makes it very easy to revert your code to a previous version thanks to the releases system. But if you have changed the database schema in a way it can’t be reverted easily (e.g., transforming data), quickly restoring a previous backup can be very useful.
Fully automated configuration management
One idea that changed my mind is how the book insists in fully automate every single configuration management step of your project. At some point, it mentions that any person who is given a new workstation should be able to run a command and have the development environment ready to work. While we don’t have that level of sophistication, we have tried hard to apply this principle in zendone.
This is the kind of practice where the most challenging part is having the discipline for implementing it. It certainly requires a lot of work, but it is not too difficult from the technical point of view.
We have tried to follow this philosophy since we started with zendone:
-
The deployment process since a code change is committed is fully automated. The only manual step is the release to production, which only required action pressing a button in our Hudson server.
-
We have created tasks for automating most of the other configuration tasks we perform.
Heroku makes it very easy to automate things, since all the operations can be executed via shell commands, without human intervention. We manage some Heroku instances for zendone. In addition to our staging and production instances, we use development instances for early testing of development branches, for Android and iPhone development, etc. We use the heroku_san gem that let you easily manage many Heroku instances for the same application.
For example, zendone requires some config vars defined in the server to run. Since the process of defining this vars is tedious and repetitive, we created a task for preparing each Heroku instance. For example, if we needed to recreate an instance for Android, we would run rake Heroku:prepare:zendone-android.
Implementing the pipeline with Jenkins
We use Jenkins (formerly known as Hudson) as our Continuous Integration server. We are using the following plugins:
- Rake for launching rake tasks.
- Git for monitoring our private Github repository and triggering the build when a change is detected.
- Chuck Norris that will remind you of facts like Chuck Norris solved the Travelling Salesman problem in O(1) time and will show an angry or happy Chuck depending on how the build finished.
We have also experimented with plugins like Join, for implementing join conditions in your pipeline, and Build pipeline, which offers a graphical representation of your pipeline, but at the end, we realized that we could implement a simple and sequential pipeline with what Jenkins already offers:
- For specifying the pipeline flow we use the built-in system for configuring downstream projects: projects which execution is scheduled when an upstream build is finished.
- Although by default each project has its own workspace directory in Jenkins, we configured the same directory for all the projects in our pipeline. This way all the stages are executed on the same code that is pulled by the initial
Startproject.
Each Jenkins step invokes a script we keep under version control with our code. With Jenkins, it is easy to end up with complex scripts hard-coded in the configuration of each project. This is dangerous and will prevent you from invoking your pipeline steps in other environments. For example, when our Start project is executed, this is the shell script it runs.
There is a commercial CI server called ‘Go’ from Thoughtworks. It looks fantastic, although I haven’t tried it. Jez Humble is behind it so I am sure it offers complete support for implementing build pipelines.
Some caveats
While we tried to apply the principles described in the book, there are some things we haven’t solved (yet).
Maybe the most important one is that we are not running our acceptance tests in a production-like instance. While Heroku makes it easy to create identical instances, it doesn’t offer a mechanism for running Cucumber tests executing a real browser. So we just run our acceptance tests in our integration server, a Mac Pro running MacOS. We haven’t had any issues due to this, but it would be much more suitable to use an identical instance for running our acceptance tests. Our staging environment, where we run our manual tests, is identical to our production one.
Another problem is that we don’t maintain each build as a physical asset with its lifetime. This means we can’t have a build version A running the acceptance tests, and a build version B deployed to staging, ready to be tested manually. All the builds share the same workspace, so this means there is only one pipeline instance in execution at a given time. We mitigate this by labeling each build in our Github repo when it starts, so the code executed in each build is traceable. Hudson doesn’t offer direct support for this. We could probably manage to make it work this way, but we haven’t needed to yet.
Finally, the book recommends to include a stage for testing nonfunctional requirements, such as security and capacity. We haven’t implemented automated capacity tests (for example, testing that the response time of your system is below some threshold with a given load). But we do have included security tests as part of our acceptance suite.
Conclusions
I think deployment pipelines are a great idea. Of course, they are not for free. Implementing its principles and automating things takes a lot of time and discipline. That is why I consider important to do it early in the development. Your pipeline will evolve as your project does, so the early you start with it the better.
The culture of automating all your software management configuration steps is also a great principle, as well as keeping all the configuration assets under version control. As I said, I think this is a matter of discipline, more that a technical challenge. Automating configuration management is not the most fun thing to do, but it starts paying off as soon as you do it.
Finally, I think the issue of writing good acceptance tests with Cucumber and Capybara deserves a post on its own. I see a couple of problems with them. They are slow and they can be fragile (although experience will mitigate the later). Still, I consider them one of the best assets we have. zendone is already quite a big piece of software, and we can add features and change things aggressively, being confident that it will work as far as our acceptance suite is green.